佳都知行交通大模型与DeepSeek优化融合,加速交通数智化升级
文 / 2025-02-13 11:36
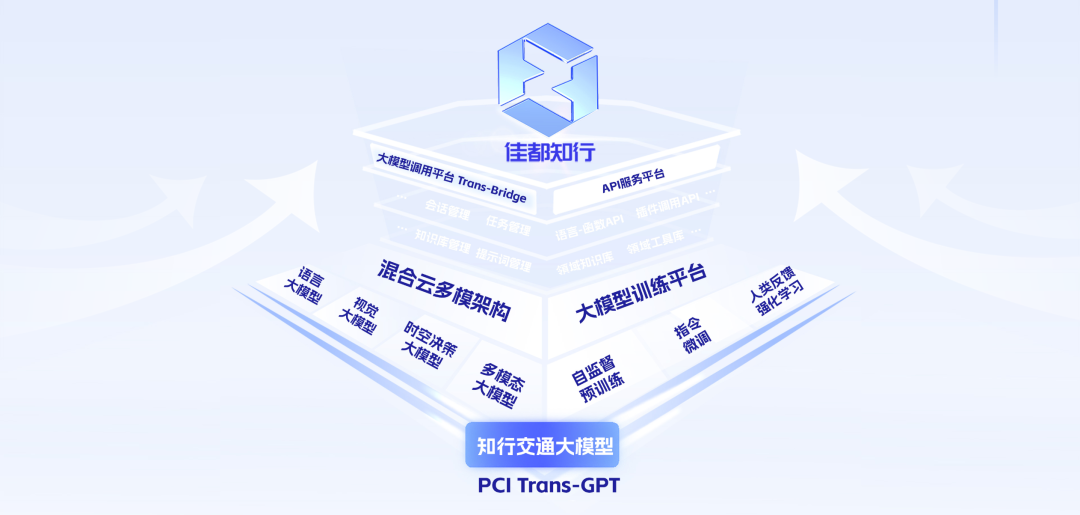
自2023年5月DeepSeek创立以来,佳都科技研发团队便密切关注其大模型技术研发进展。DeepSeek在2023年11月、2024年5月、2024年9月先后发布并开源的V1、V2、V2.5版本大模型,其技术报告中不断迭代的高效训练与推理技术,与佳都科技持续深耕的“模型沙盒”优化技术体系高度契合,通过消化与再创新,有效加速了佳都科技自研垂类大模型——佳都知行交通大模型的迭代研发。
早在2023年佳都科技就发布了全球首个交通行业大模型——佳都知行交通大模型,并于2024年迭代升级至V2.0。同时,2024年佳都科技基于FP8等预训练技术,使知行大模型预训练效率较24年年初提升了150%以上。同时,团队在国产千卡GPU集群上完成了大模型优化训练方法的验证。通过结合多种推理优化技术,同等参数规格知行大模型的部署成本较年初大幅降低了一个数量级,并在超过8款国产GPU上完成了推理适配,并凭借卓越的技术实力荣膺“华为昇腾最佳原生开发伙伴”。
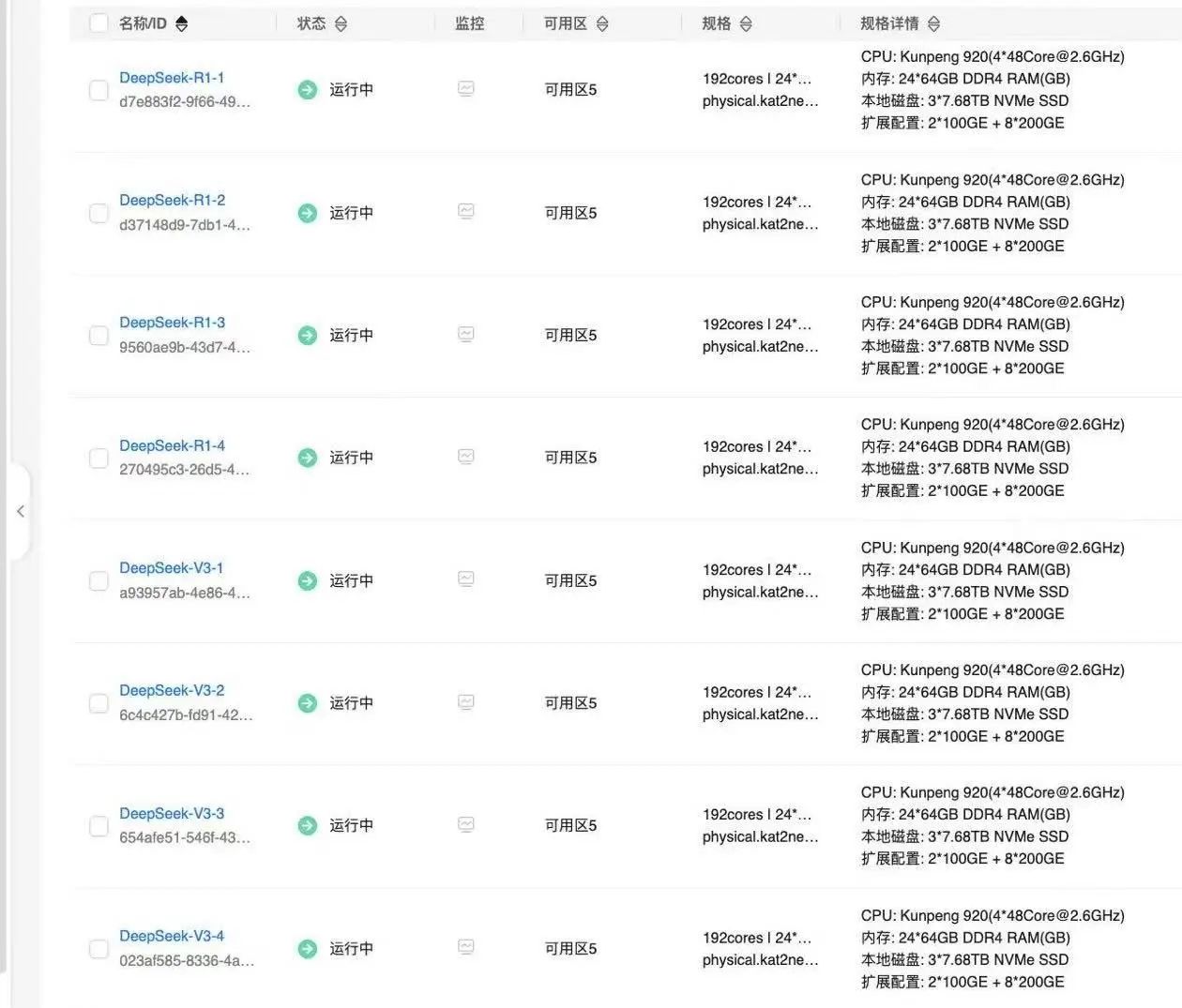
DeepSeek-V3/R1满血版,在佳都GPU集群上的部署
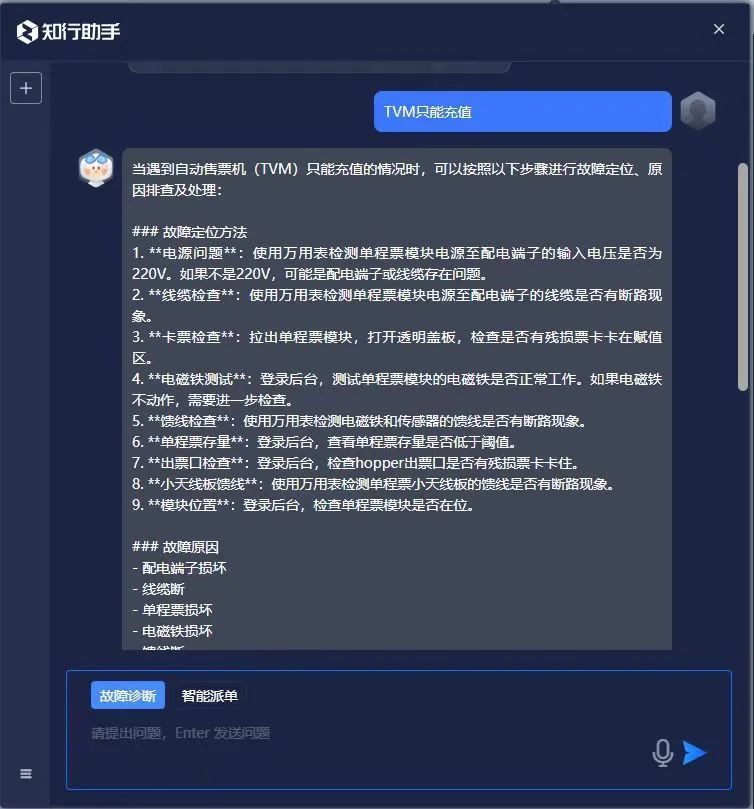
经过一系列严谨的对比验证,DeepSeek-R1作为率先成功复现OpenAI o1/o3的开源参考实现,展现出强大的技术实力,可助力交通智能体在深度推理能力场景的落地。例如,在城市交通信号优化控制、轨道交通智能运维等关键场景中。目前,公司已在部分生产环境完成了私有化部署DeepSeek模型接口的切换,有力支撑了交通场景日常业务中的智能化应用,为行业数字化转型注入了新的动力。
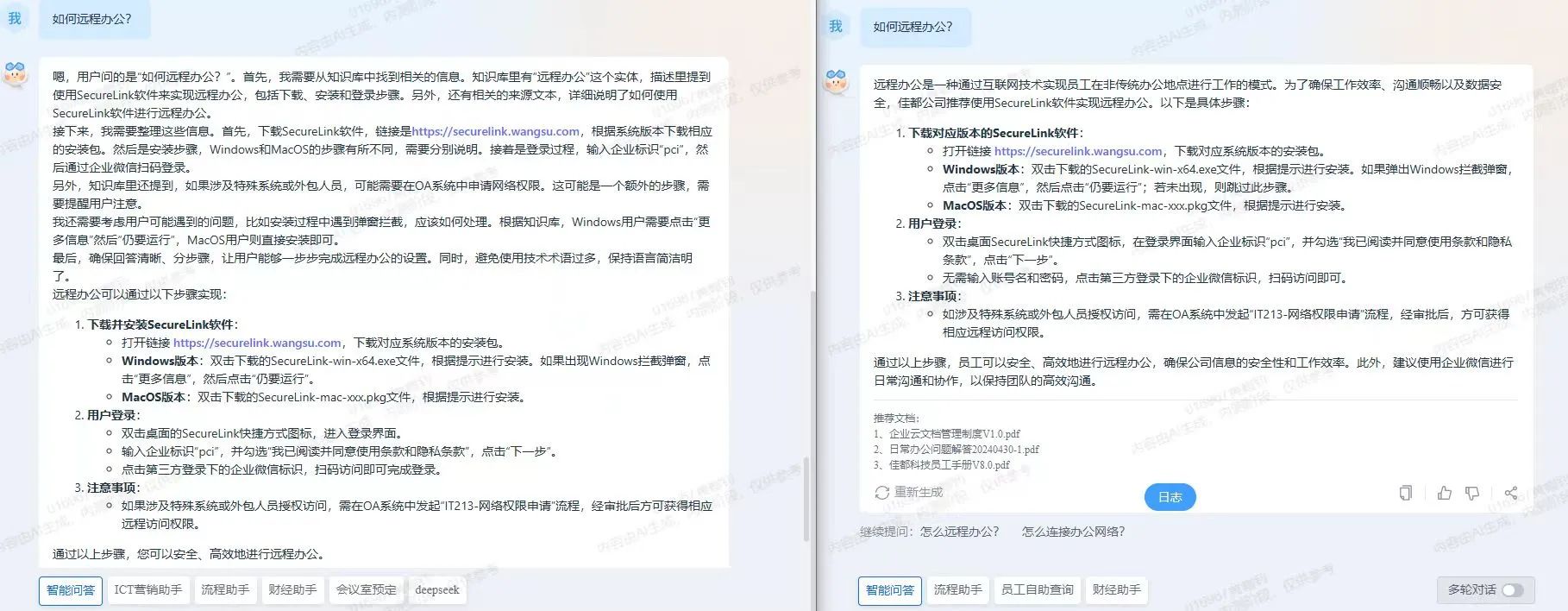
图为DeepSeek接入前后,佳都知行大模型在智能运维生产场景测试对比(右为接入后)